
ここ数年、機械学習分野では自己注意(self-attention)と呼ばれる仕組みに基づいた学習モデルが様々なアプリケーションに適用され、その性能・汎用性の高さから大きな注目を集めていました。代表的なモデルがTransformerと呼ばれるもので確固たる地位を築いていますが、優れた性能を発揮する上でAttentionが真に重要な役割を果たしているのかは明らかではありませんでした。
そこで登場したのが、Attentionを用いず多層パーセプトロン(MLP)ベースのモデルで優れた性能を発揮したgMLP(ゲート付きMLP)です。Transformerばりの性能を示すということで大きな話題になっているこちらのモデルについて、特に画像認識の方法を例にとって図解したいと思います。
文献はこちらです。[2105.08050] Pay Attention to MLPs
また実装に関しては以下のレポジトリを参考にしました。- モデルの概要
- パーツ① 画像のパッチ処理とベクトル化
- パーツ② チャネル内(トークン内)の相関
- パーツ③ チャネル間(トークン間)の相関
- (オプション)パーツ④ 自己注意機構の活用
- 予測精度の評価
- おわりに
モデルの概要
gMLPモデルの概要が、原著論文から引用した以下の図になります(①-③の番号は私がふりました)。gMLPは自然言語処理にも画像認識にも利用できますが、まず初めに①学習用データをベクトル化します。その後モデルに入力し、②チャネル方向へのFFN(Feed Forward Neural Network)をかましチャネル内で相関を取ります。続いて③Spatial Gating Unit (SGU)により複数のチャネル間での相関を取ります。最後にもう一層チャネル方向へのFFNを取り、1つのgMLPユニットが出来上がります。これを何層か繰り返すことで学習モデルが構築されます。
とまぁ非常に素朴なモデルのように見えますが、これだけ見ても何故このモデルが優れた精度を発揮しうるのか良く分かりません。またより完全に理解するために実際にどのような形でデータが処理されてモデルを流れているか、イラストで確認していきましょう。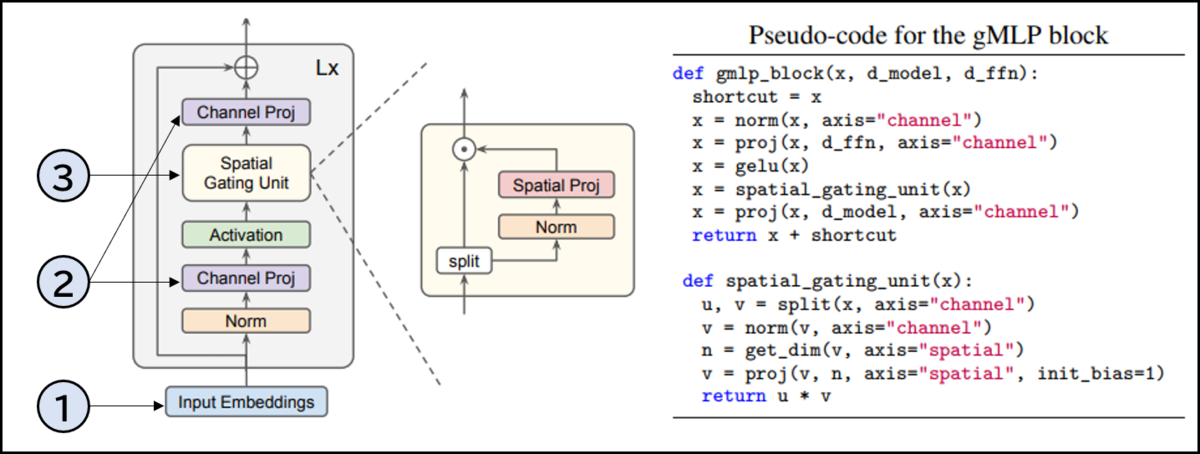
パーツ① 画像のパッチ処理とベクトル化
gMLPは画像を入力としてそれらをクラス分けすることができますが、どのようにしてMLPで画像を処理するのでしょうか?そのためにはまず、画像を複数のパッチ(小区分)に変換します。
以下の例では、元の画像を4つのパッチに分割しています(実際はより細かく分割します)。各パッチは(チャネル数, パッチ高さ, パッチ幅)のテンソルで表現されますが、これを1列に順に並べることで1次元のベクトルとして表現します。つまり要素数が(チャネル数×パッチ高さ×パッチ幅)である配列です。さらに、この配列に対して全結合層を通すことにより任意の要素数の1次元配列に変換します。これにより画像のベクトルデータとしての埋め込みが完了です。

パーツ② チャネル内(トークン内)の相関
入力データができたら、次はそれらを全結合層に通して適当な活性化関数(GELUなど)を用いて出力します。処理としてはシンプルです。これにより1つ1つのパッチ内部での相関を取ることができます。
パーツ③ チャネル間(トークン間)の相関
次が、gMLPの中核をなすSGUの処理になります。すでに②までの処理でパッチ内部での相関が計算されたことになっているので、次は各パッチ同士の相関を取る必要があります。
SGUではまず初めに、渡された配列をチャネル(パッチ)方向に関して2分割します。片方はそのまま保存し、もう片方の配列に対して処理を行います。相関の取り方には色々な方法が想定でき、通常の線形結合でも定義可能です。たとえば入力データのサイズが(パッチ数, 次元数)の時、このデータの左から(パッチ数, パッチ数)の配列をかければチャネル(パッチ方向)の相関を取ることができます。
また、今回の記事の作成にあたり参考にしたGithubの実装ではこの計算にカーネルサイズ1の1次元畳み込みニューラルネットワークを活用しています。これにより、チャネル(パッチ)内での相関は取らず、チャネル(パッチ)間の相関のみを計算できます(pointwise convolutionの考え方ですね)。下記の図もこの実装方法にならって図示しています。
そして最後に、分割して放置していた相方の配列と要素ごとの積を取る(ゲート処理する)ことで最終的な配列を生成します。そのため、入力の配列に比べ次元数が1/2に減っていることになります。
さて、以下の図にも記載しましたが、SGUにself-attention処理を追加することで予測精度が向上することを筆者らが報告しています。Attentionにより分割後のデータと同じサイズの配列を生成し、それらを要素ごとに加算することでこの処理が行われます。せっかくなのでself-attention処理の概要についても振り返ってみましょう。

(オプション)パーツ④ 自己注意機構の活用
以下の図がself-attention処理の概要です。かつて本ブログで自然言語処理とTransformerを取り上げた際に作成したものですが、単語数をパッチ数と読み替えれば計算方法は同じです。
入力となるベクトルを次元数に対して3分割し、キー、クエリ、バリューと呼ばれる3種類のテンソルを生成します。続いてキーとクエリの積を取り、適当な量でスケーリングした後ソフトマックス活性化関数を通すことで、単語(ここではパッチ)の重要度を示すテンソルを作成します。この重要度テンソルを未処理のバリューテンソルにかけることで、重要度に関して重みづけられたテンソルが生成されます。gMLPのSGUでは、この重要度によって重みづけられたテンソルを加算することでパッチ間の相関がより良く取り込まれるようになり予測精度が向上したようです。

予測精度の評価
さて、肝心のモデル予測精度がこちらです。まずは画像認識について、ImageNetデータベースの画像分類タスクを行った結果従来のTransformerベースの最良モデルの1つであるDeiTにほぼ匹敵することが分かりました。ここではAttentionを使用しないゲート付きMLPでの処理に基づいたモデルが用いられたことから、アテンションフリーのモデルの価値が再発見されるきっかけになる重要な結果と言えます。

おわりに
gMLP、およびアテンション付きgMLP(aMLP)の内容を図解することで、具体的なデータの流れが把握できたのではないでしょうか。画像認識分野ではgMLPがTransformerベースの手法に匹敵する精度を収めたことで、今後はアテンションフリーなモデルの開発に再び火が付く可能性があります。
一方で自然言語処理タスクでもTransformerと肩を並べる結果が得られましたが、本研究の結果をもってアテンションは終わった、Transformerは終わったとするのは早計な気がします。なぜならアテンションをgMLPに適用することでより優れた性能が得られている訳ですから。結局、MLPが良いのか、Attentionが良いのか、やはりconvolutionが良いのか、その問いに答えを与えるにはまだ時間がかかりそうです。ただ、これらの三つ巴のバトルがより混沌としてきたという印象は否めません笑。