
こんにちは。前回に引き続き、拡散モデルに関する話題を取り上げます。拡散モデルとはGoogleのImagen等に活用されている話題の生成モデルであり、一部のタスクでは最も研究が進んでいる生成モデルGAN(敵対的生成ネットワーク)の最高性能を上回ることが報告されています。拡散モデルにはスコアベースモデル、拡散確率モデルなど幾つかのタイプがありますが、今回はスコアベースモデルについて解説を行います[1,2,3,4]。
以下は、スコアベースモデルによる画像生成の実例です。人間の目にはフェイクであることが分からないほどの精度で、画像が生成できています。

エネルギーベースモデルの復習
スコアベースモデルの解説の前に、その基礎となるエネルギーベースモデル(EBM)の考え方を復習します。EBMでは任意のパラメータを持った関数 ここで、連続値の場合は
は任意のデータ
に対して常に > 0であり、積分(又は総和)すると1になることから確率密度としての要件を満たします。EBMでは対数尤度を最大化するためにパラメータに関する勾配を計算しました。
ここで問題となるのが、正規化定数の計算です。EBMではマルコフ連鎖モンテカルロ法(MCMC)とcontrastive divergence(CD)を用いることで問題を解決しましたが、MCMCは収束までの時間が遅く、またCDはモデルからデータをサンプリングする必要があり計算コストが重いという問題があります。これらの問題を解決するための手段が、スコアベースモデルです。
EBMの詳細は過去記事をご覧ください。
dajiro.com
スコアベースモデルの概要
EBMではを解析対象とします。これをスコア関数と呼びと表します。正規化定数
は確率変数に依存しませんから、
となり正規化定数に依存せずに表現することができます。
スコアベースモデルでは、モデルのスコア関数と真のデータ分布の勾配のフィッシャー距離を最小化することで学習が行われます。
]
しかし真のデータ分布の勾配の計算が難しそうです。ここでスコアマッチングと呼ばれる手法を用いることで、直接データ分布の勾配を計算しなくてもフィッシャー距離を最小化することができます。
スコアマッチング
上で定義したフィッシャー距離を計算するために、]
第二項はスコアのヤコビアンのトレース計算を表しています。この式はモデルのスコアのみを含んでいることから、目的関数を計算することができそうです。一方で問題点もあり、ヤコビアンの計算はデータの次元Dに対して
のオーダーで計算量が増加するため、データのサイズに対してスケールさせることが出来ません。
そこで、この問題を克服するために考案されたのがデノイジングスコアマッチングとスライスドスコアマッチングです[6, 7]。
- デノイジングスコアマッチング
Vincent[6]はクリーンなデータとノイズ付きデータ
に対して目的関数を以下のように定義しました。
]
]
これにより、モデルから出力されるノイズデータは、ノイズ付きの真のデータに近づこうとします。真のデータに関する第二項の計算は難しそうですが、ここでカーネルトリックを用い、ガウスカーネルを用いて以下のように表現することにします。
データがn個あるとすると、目的関数の期待値の計算は最終的に以下のように書き下すことができます。
]
スコア関数のヤコビアン計算を消去することが出来ました。これで高次元データにもスケールするスコアマッチングが可能となります。
- スライスドスコアマッチング
高次元空間における勾配の比較をより単純な問題に落とし込むために、Songらは勾配ベクトルを1方向を向いたランダムベクトルに射影することを考えました[7]。

このとき、フィッシャー距離は以下のようにベクトルの積を用いて書くことができます。さらに部分積分を用いてへの依存性を消去することも可能です。
]
]
ここで注目すべきは、スコア関数のヤコビアン計算が、ベクトルの内積に対するヤコビアン計算に置き換えられることです。
(上式の第一項の変換)
これによりスコア関数ネットワークの出力ノードを1つに集約でき、自動微分を一回実行するだけで、ランダムベクトルに射影したときのデータに対する勾配を計算できるようになります。一方で従来型のスコアマッチングでは、出力ノードの個数はデータ次元数Dだけ存在していたため、D回の自動微分が必要でした。ランダムベクトルの個数MがDより大幅に小さいとすると、スライスドスコアマッチングは大幅に計算量を縮減できるスケーラブルな方法と言えます。
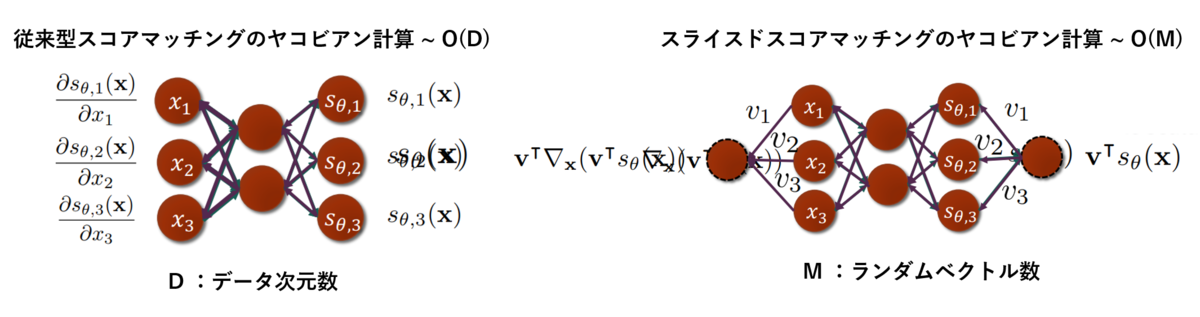
サンプリング
真のデータ分布の勾配を近似することが出来たら、それを用いてデータをサンプリングします。エネルギーベースモデルに関する記事でも言及したように、ランジェバン動力学を用いたサンプリングを行います。初期サンプルは何らかの事前分布から生成し、以下の式に基づいて繰り返し更新することで最良のデータを生成します。ここではガウス分布から生成されるノイズです。
を無限小に、
を無限大にもっていくことで解は収束し、最も妥当なサンプルが生成されると考えられます。また学習によって
は
によって近似されており、これを代入することでサンプルが得られます。
これまで結果をまとめたのが以下の図です。まずは真のデータ分布があり、モデルのスコア関数がこの勾配を近似するようにスコアマッチングを用いて学習を行います。得られた学習済みスコア関数を利用してデータをランジェバン動力学によってサンプリングすることで元のデータを模倣した新しいサンプルが生成されます。

スコアベースモデルの課題
このように定義したスコアベースモデルには、ある問題があります。それを理解するために、多様体仮説を考えます。多様体仮説とは、実世界のデータは高次元空間に埋め込まれた低次元多様体に集中している、ということを経験的に主張したものです。スコアベースモデルではデータに関する勾配は高次元空間全域で計算しているため、データが少ない領域ではスコアの推定が困難になります。スコアが計算できなければ、ランジェバンダイナミクスではデータの低密度領域を探索することができません。
多段階のノイズ付加
多様体仮説に基づく問題を回避するために、元のデータにノイズを与える、というアイデアが用いられました。データに完全にランダムなノイズを与えることで、データは低次元多様体に拘束されることなく高次元空間全域に存在するとみなすことができます。ノイズは段階的に付与され、最終的にはデータは完全なノイズとなります。逆に、ノイズを段階的に除去する(アニールする)ことで、データ分布からのサンプリングを行うのがスコアベース拡散モデルの中心的な考え方です。ノイズを段階的に付与する過程は、以下の図のように理解できます。
ガウシアンノイズを付加したときの真のデータ分布は以下のように書くことができます[9]。
このノイズ付与分布に対する勾配を、スコア関数
で推定します。文献[3]ではこのスコア関数をNoise Conditional Score Network(NCSN)と呼んでいます。全部でL段階のノイズが付与されるとしたとき、NCSNを訓練するための損失関数は以下の式で定義されます。
]
と書けます。ここではウェイトです。上記で言及したスコアマッチングを用いて上式を計算可能な形へ変換し、学習を行います。
サンプリングは、一様分布などの事前分布から生成したデータを出発点としてannealed Langevin dynamicsを用いて行います。L段階のノイズレベルごとに、異なるステップ幅を用いてT回のランジェバンMCMCを実行しサンプルを生成します。得られたサンプルを出発点として、ステップ幅を変えながら再度サンプルを生成します。これをL回繰り返すことで、最終的なサンプルを生成します。完全にランダムなデータから、サンプルが実際に生成される過程が以下の図です。リアルな画像が生成されている様子が見て取れます。

更なる改良
以上がスコアベースモデルの概要となります。生成画像の更なる高精度化のために、多くのテクニックが既に開発されています。ここでは詳細は触れませんが、そのうちいくつかをピックアップします。上記の説明ではノイズの付加を段階的に行っていましたが、Songらはこれを連続的な過程と見做すために確率微分方程式として定義しています[4]。ノイズからデータを生成するための確率微分方程式のソルバーとしてEuler-Maruyama法を用い、さらにPredictor-Corecctor機構を導入し、ステップごとに予測されるサンプルの品質をスコア関数を用いて補正する、といったテクニックを用いることで、素朴なスコアベースモデルから大幅な高精度化を実現しています。また、スコアベースモデルと異なるタイプの拡散モデルとして、拡散確率モデルが知られています。そちらのアプローチは以下のブログが詳しいです[10]。数式が多く読み進めるのが大変ですが、一言で述べるならノイズの除去方法をニューラルネットワークで学習しています。Kerasによる画像生成例も公開されています[11]。
おわりに
以上、スコアベースモデルの概要について説明しました。様々なテクニックが盛りだくさんで学習コストが非常に高く、GANやVAEより難しく感じました。最近は有志による英語ブログ記事が増えており、youtubeでの日本語解説も行われているので徐々にハードルは下がっていくでしょう。拡散モデルのスピーチ生成や分子生成等の応用例についても、学習を続けていきたいと思います。出典
[1] https://arxiv.org/abs/1503.03585[2] https://arxiv.org/abs/2006.11239
[3] https://arxiv.org/abs/1907.05600
[4] https://arxiv.org/abs/2011.13456
[5] https://www.cs.helsinki.fi/u/ahyvarin/papers/JMLR05.pdf
[6] http://www.iro.umontreal.ca/~vincentp/Publications/smdae_techreport.pdf
[7] https://arxiv.org/pdf/1905.07088.pdf
[8] https://deepgenerativemodels.github.io/assets/slides/cs236_lecture13.pdf
[9] https://yang-song.net/blog/2021/score/
[10] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[11] https://keras.io/examples/generative/ddim/