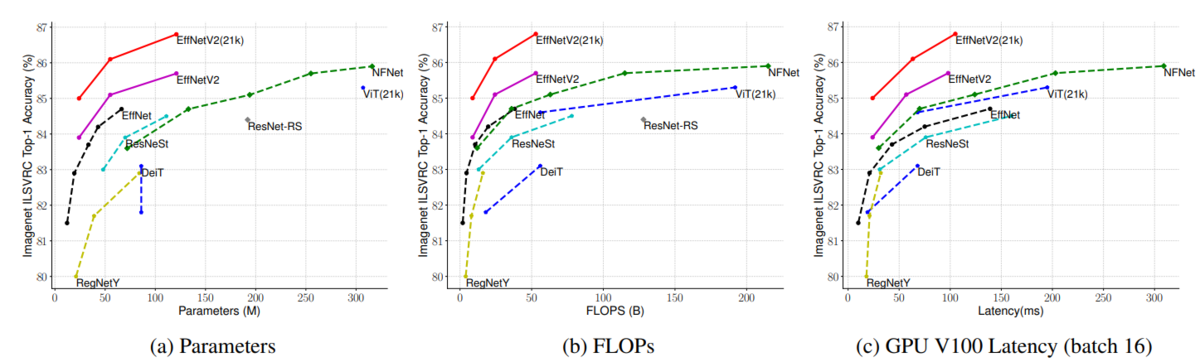
機械学習を使った画像認識モデルの進化が止まりません。2019年以降に絞ってみても、EfficientNet, Big Transfer, Vision Transformerなど数多くのモデルが提案され、当時最高の予測精度が報告されてきました。そして最近になり注目を集めているのが、従来手法より軽量でかつ高精度なモデル:EfficientNetV2です。なんと、最近の最強モデルVision Transformerと同様の計算リソースを使って5倍から11倍高速で、かつ2%も高性能化に成功したと報告していいます。どのような手法を用いたのか、順を追って確認していきましょう。
原著文献はこちらからご参照下さい。https://arxiv.org/pdf/2104.00298.pdf
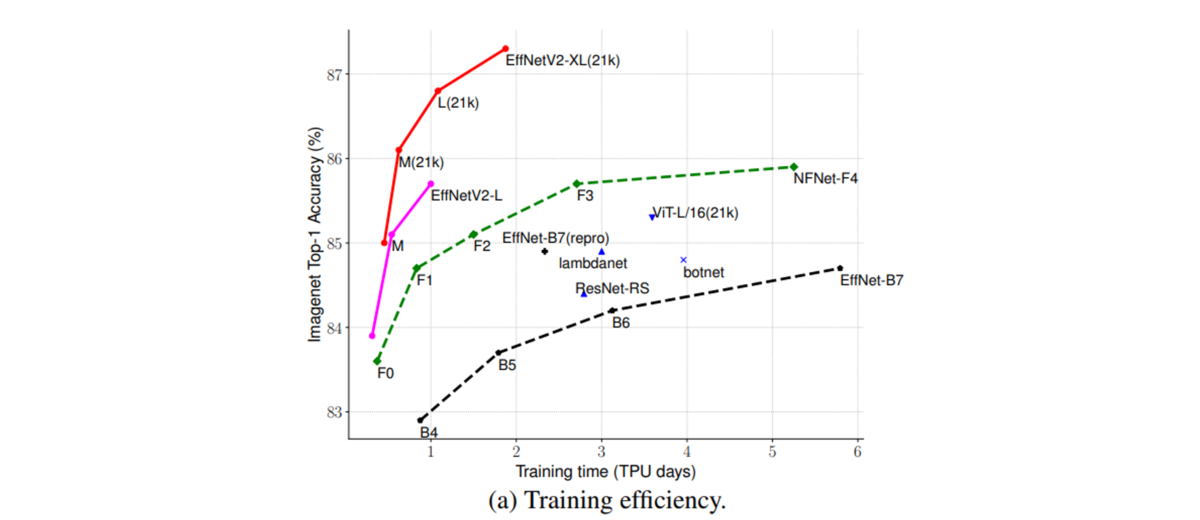
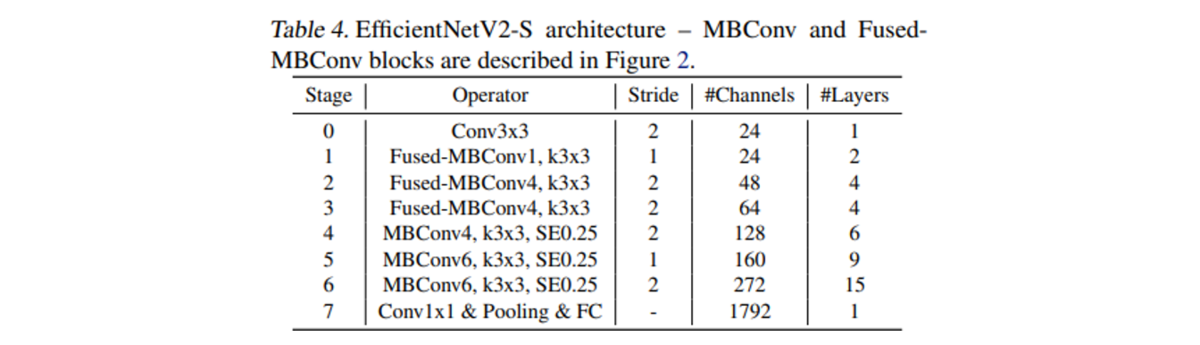
EfficienetNetV2のアーキテクチャ探索
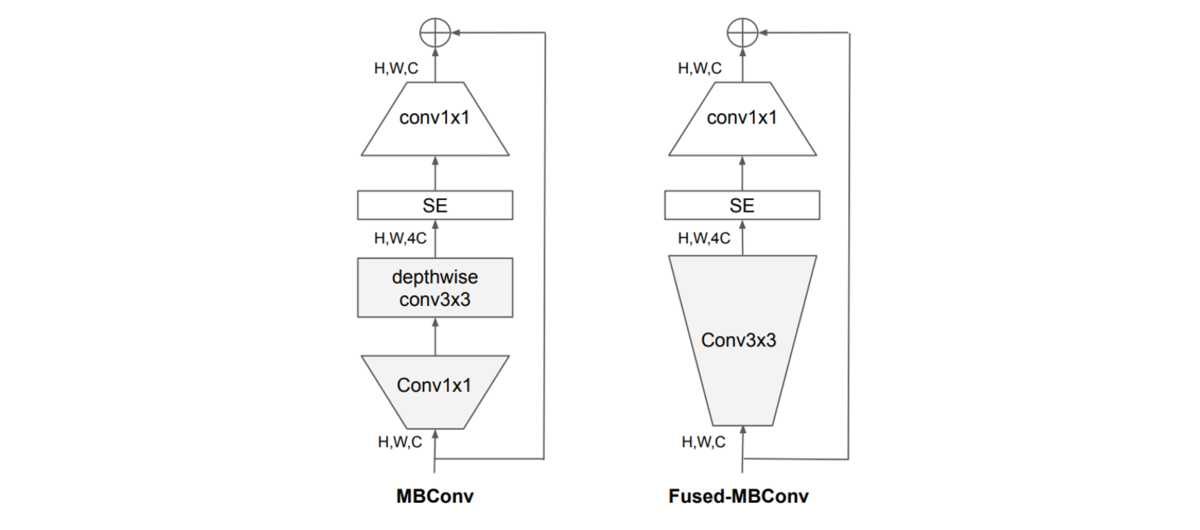
パラメータを増やし大規模化したモデルでは、たとえ精度が良くても推論速度が遅かったり膨大な計算資源が必要になる(数千枚のGPU!)といった問題があります。パラメータ数を減らすために、従来の畳み込み処理ではなくdepthwise convolutionと呼ばれる手法で畳み込むことが有用であることが知られています。空間的な畳み込みを行うことは共通していますが、チャネル方向の相関をあえて無視することでパラメータ数の大幅な低減に成功しています。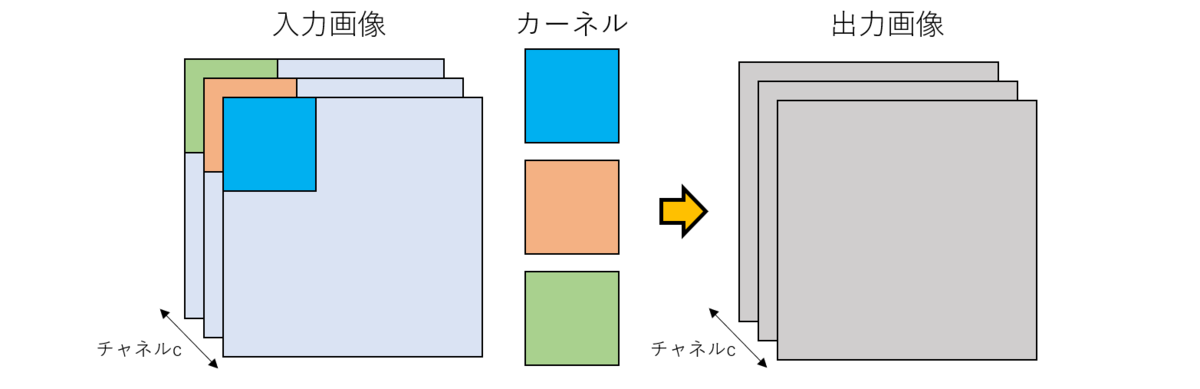
プログレッシブラーニングと適応型の正則化
画像認識におけるプログレッシブラーニングとは、学習の過程でモデルに入力する画像サイズを変更することを意味します。大きな画像サイズを入力とした学習では訓練時間が遅いことが知られており、これを克服するために小さなサイズの画像を入力として学習を開始し徐々に大きくしていくという戦略を取ります。このような手法は過去の研究でも採用されていましたが、精度の低下につながることが報告されていました。著者らは、これは学習の正則化を均一に行っていることが問題であると指摘し、画像のサイズに応じて正則化を適応することが重要であると提案しています。つまり、小さい入力画像に対しては弱い正則化、大きい入力画像に対しては強い正則化をかけます。なお、ここで正則化というのは訓練用データへの過学習を防ぐために訓練データを加工したりネットワークを調整することを指します。具体的には、Dropout, RandAugment, Mixupの3種類の正則化手法を採用しています。 訓練時に用いられるステップごとの入力用画像は以下のイメージのように変化していきます。訓練開始時は小さい画像で、加工の度合いが小さく容易にパンダと認識できます(少なくとも人間にとっては)。しかし学習が進捗していくと画像サイズを大きくし、回転や他の画像とのミックスの度合いを増やすことで学習の難易度を徐々に上げていきます。このような工夫を施すことによって、EfficientNetV2は軽量かつ高性能という素晴らしいパフォーマンスを発揮するに至りました。

おわりに
この研究の重要なポイントは、NASによるAutoMLと適用型正則化によるプログレッシブラーニングの導入にあるかと思います。前者は現代の機械学習の大きな潮流で、ネットワークのアーキテクチャ設計のような機械学習エンジニアの仕事の在り方を変える可能性があります。また、後者はありそうで意外となかった技術です。強力ですが理解しやすいアイディアなので今後の研究にも使われるようになる可能性があります。高効率・高精度な学習モデルの探索はまだまだ発展していきそうな気配があり、目が離せませんね。